
개발
하둡 기초 개념
31514
2024. 9. 30. 12:46
대용량 분산 서비스가 필요한 이유
- 대용량 데이터를 손실 없이 보관하기 위해
- SQL과 같이 구조적 데이터 뿐 아니라, 비구조화/반구조화 데이터를 처리하기 위해
- 순차적 처리보다는 병렬 처리가 더 빠르니까
대용량 분산 서비스의 필요 조건
- 분산 파일 시스템과 분산 컴퓨팅 시스템
- 몇 대의 노드(서버)가 고장나도 신뢰성을 유지할 수 있는 Fault Tolerance
- 용이한 확장
하둡 1.0

- HDFS(분산 파일 시스템)과 MapReduce(분산 컴퓨팅 시스템)으로 구성
- 하지만 MapReduce가 너무 저수준이라 사용자들이 어려움 호소
- MapReduce 위에 고수준의 프레임워크 Pig, Hive, Presto 등 출현
하둡 2.0
- MapReduce 대신 YARN
- YARN은 고수준 프레임워크를 사용하는 사용자들을 위해 조금 더 범용적인 자원 관리 프레임워크(Resource Management Framework)
- HDFS도 신뢰성과 견고성을 높여 HDFS2로 발전
- YARN위에 MapReduce, Spark, Tez 등을 올려 사용
HDFS
<개념>
대용량 분산 파일 시스템
<특징>
하나의 파일을 기본값 128MB 크기의 블록으로 나누어 여러 서버에 저장
서버의 고장을 대비하여 최소 3대 이상의 서버에 저장
<구조>
- Name Node(Master)는 어떤 파일이 있고, 파일이 어떤 Data Node(Slave)에 나뉘어져 있는지에 대한 정보를 저장하는 디렉토리
- 특정 Data Node가 고장나면 해당 Data Node에 있던 블록들을 파악하고 새로운 Data Node에 정보를 저장하여 3개 이상을 유지
- Data Node가 가지고 있는 파일 시스템에 데이터 블록 저장
<Name Node 이중화 방법>
- Active/StandBy - Name Node에 장애가 발생하면 즉시 StandBy가 대체
- Secondary - 그냥 복제본, 장애가 발생하면 사용자가 직접 복구 필요
MapReduce
<개념>
대용량 분산 컴퓨팅 서비스
<특징>
데이터 셋은 key-value의 집합만 가능하고 불변성 지님
Map은 입력으로 들어온 key-value를 다른 key-value 리스트로 반환
Reduce는 Map의 출력 중에 같은 key를 가진 데이터를 모아서 처리
Reduce의 출력은 HDFS에 저장
<셔플링>
Map의 출력을 보고 어느 Reduce로 갈지 정하고, 네트워크로 송신하는 과정
<Sorting>
Reduce에 들어온 파티션을 정렬하고 같은 키를 갖는 value 병합
<Data Skew>
Map에 들어오는 데이터에 따라 Task 수가 결정되고, Reduce는 개발자가 직접 지정
이에 따라 Map이 출력하는 키의 분포가 특정 Reduce에 몰릴 수 있음 → 하나의 Reduce만 처리해야 하는 데이터의 양 증가
<문제점>
낮은 생산성 → 데이터 포맷 1개, 2가지 오퍼레이터, 어려운 튜닝
배치 처리만 가능
YARN
<개념>
MapReduce가 너무 저수준이라 탄생한 범용적인 리소스 매니저 프레임워크
<동작 과정>
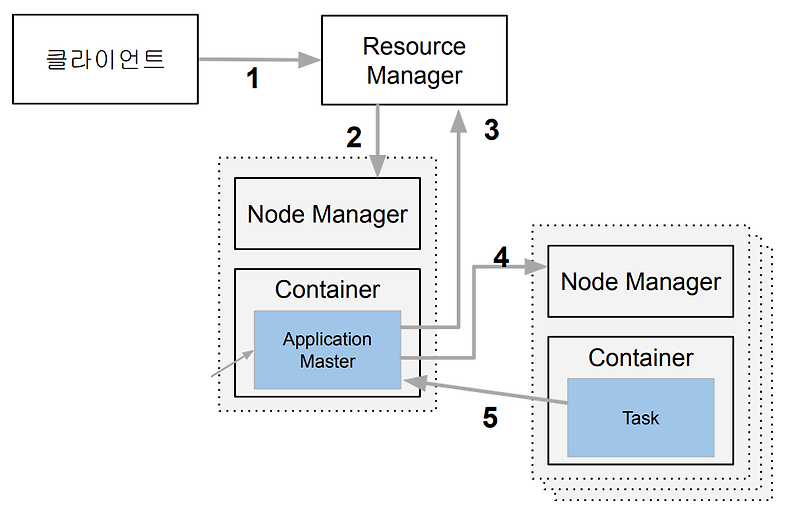
- 클라이언트가 리소스매니저에게 실행 코드와 환경 정보 등을 넘김
- 리소스매니저가 노드 매니저 안의 컨테이너에 애플리케이션 마스터 생성
- 생성된 애플리케이션 마스터가 리소스매니저에게 코드를 실행하기 위해 필요한 정보 요청
- 리소스매니저에게 받은 정보를 바탕으로 노드 매니저에게 필요한 컨테이너 수 전달
- 생성된 태스크가 주기적으로 애플리케이션 마스터에게 상황 보고(Heartbeat)